Reinforcement Learning in Production Made Easy
Introduction
Reinforcement Learning (RL) is one of the exciting and promising areas of Artificial Intelligence/Machine Learning. Regardless of its potential, running a scalable reinforcement learning model in production is still a tedious task. In other words, it is fair to say that it is common to have more production running classical (un)supervised learning models than RL models. However, the scenario is rapidly changing with the release of many open-source & commercial tools in recent years.
Reinforcement Learning
RL is often used to solve problems where there is no single optimal way of solving the problem. Rather, the problem can be solved in multiple ways with respect to various (ever-changing) objectives and constraints. These kinds of problems often (although possible) have difficulties in using off-line data (a typical requirement for (un)supervised learning models) for building models to solve their problems. They may need a system that can constantly interact with the underlying source to solve the problem. Due to this nature, these problems pose an additional challenge of either coding the problem or creating a digital-twin for the problem. This is often referred to as an environment in RL terms. A typical RL problem setting contains the following faculties (see Figure):
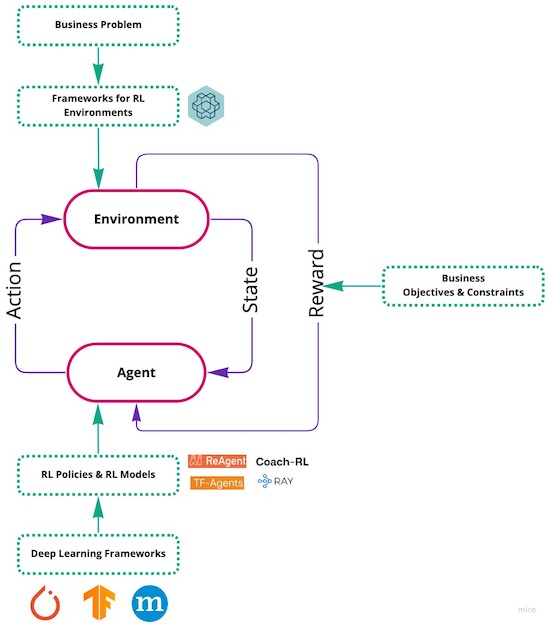
Faculties of Reinforcement Learning
- Environment The coded problem which is to be monitored or controlled continuously. This incorporates the features which define the nature of the problem (state), the means by which its nature can be influenced (actions), the quantifiable impact of such means which are executed on the environment (reward).
- State An instance of the environment at a given time (i.e., a set of parameters that defines the current nature of the environment).
- Action A set of actions that can be performed on the environment to influence the state of the environment.
- Reward A quantity that will be outputted by the environment when an action is taken on it. The business objectives and constraints of the problem are often incorporated in the form of reward.
- Agent A RL faculty to propose a single or a set of actions given a state of the environment. This faculty often incorporates key elements: a policy and a model.
Difficulties
If we have to develop a RL solution to a problem from scratch, the problem has to be first coded as an environment. If the problem has an existing simulator which can take on actions and can throw out state and reward, one can move to the development of RL agent immediately. If not, one has to first formulate the problem as an Environment. The following tools, among many others, are often used for this:
The next big step is to use one of the suitable machine learning frameworks (such as PyTorch, TensorFlow, etc.) to code the RL agent (i.e., the policy & the RL model) and get them integrated with the environment. Once such an integration is done, the agent can be trained by continual interaction with the environment. Once the training is carried out, both the policy and the model are to be integrated with an API app to serve via endpoints. However, it's much easier said than done. Understanding the training and the behavior of RL agents is often cumbersome. Besides, creating a development and a production environment (i.e., docker image for an example) with necessary tools are often time consuming. Additionally, one has to focus on the serving part of the agent such as load balancing, scaling (e.g., running in Kubernetes clusters), etc.
Changing Landscape
The difficulties of training and serving RL models are, however, diminishing with the advent of many tools such as
- coding the problem environment as accurately as possible
- experimenting various business objectives & constraints (i.e., rewards)
- experimenting various scopes and complexities of the problem to be solved
- plugging the trained RL agent(s) in the right context to solve the actual use-case(s)
- white-boxing the agent's training and predictions with potential explainable AI tools.